how-to-develop-perfect-crud
Translations: EN(you are here), RU
🤔 What is this?
This article is an attempt to combine good practices that are useful to keep in mind and apply when developing a backend application.
It can be used as a checklist if:
- You are starting a greenfield project and want to ensure that best practices are used right from the start.
- You received a test assignment and have decided to move forward with it.
🤔 Does this article only cover backend apps?
Because the author’s expertise lies mostly on the backend side, most suggestions will be useful for developing backend apps. However, a lot of the points covered in this article can also be handy for other types of development.
🤔 There is a lot in here, do I really need all of this?
The more features and practices you adopt in your project, the better. Applying all of them at once would be hard so consider your time 🕒 and effort 💪 to prioritize specific practices.
🤔 “This article is missing information about technology X”
If you have a proposal about covering a specific technology here, don’t be shy:
- Open an issue ✅
- Open a PR ✅
📖 Table of Contents
- Repository
- Code Style
- ✔️Tests
- ⚙️Configuration & Infrastructure around Code
- API Design
- Authorization & Authentication
- MVC Explanation
- 📐✏️👷♀️Architecture, Design Patterns, Refactoring, etc
- 🔒CRUD: Validations
- CRUD: Database
- CRUD: Operations
- External API Calls, Long-running tasks (And why we need message queue)
- 📈Logs and Metrics
- 🛡️Security
- CORS Headers (Cross-Origin Resource Sharing)
- Cache
- WIP: Transactions, Locks, Isolation Levels, ACID
- WIP: Full Text Search
Repository
- Codebase has to live on a public or private Git repository (Github / Gitlab / Bitbucket)
- Repository settings must disable force pushing into (
push --force) into main branches (master,main, release branches) - ‘README’ should contain:
- info about the project
- short summary of tooling and the tech stack
- instructions for setting up and launching the application
- Use feature branches, pull requests. Refer to this great article with comparison of different Git Branching Strategies.
- Use readable commit history. Here is a good set of rules Conventional commits
- Set up Continuous Integration (Gitlab CI / Github Actions)
feature/and master branches should be set up with:- test runners and coverage stats
- linting
- Setting up Continuous Delivery - app deployment into different environments (e.g. test/staging/prod) would be a huge plus!
- Optional: Set up dependabot
Code Style
Before development:
- Have a working editor or an IDE:
- VS Code
- Visual Studio
- PyCharm
- IDEA
- Vim, emacs
- EditorConfig plugin / add-on is up and running for your editor
- Set up Code formatters:
- Rubocop for Ruby
- Pylint/Black/PEP8 for Python
✔️Tests
- Install libraries for writing various test types (unit, integration). For instance:
- Pytest for Python
- RSpec for Ruby
- Testify, testcontainers for Golang
- Test coverage is calculated automatically after each test run
- Apply AAA (Arrange Act Assert) pattern when writing unit tests
Try to adhere to the [testing pyramid] (https://martinfowler.com/articles/practical-test-pyramid.html) principle. Note that different test types require different tools. For end-to-end (e2e) testing you can try using Selenium or Cypress. Integration tests can be added via testcontainers.
⚙️Configuration & Infrastructure around Code
- Have
dockeranddocker-composeinstalled on your local machine - There is a Dockerfile in your repository which can be used to build your app into a
Docker container- Best practices when writing a Dockerfile for a Ruby application (although, these tips can be useful for other languages)
- Google Cloud: Best practices for building containers
- All app dependencies are listed in a
docker-compose.ymlfile - Setting up and launching your application should be as easy and straightforward. It is possible that you may need to write some additional
base/zsh/powershellscripts - Your application should have multiple environments (development, prod, test)
- Use a suitable application server for your
productionenvironment. For example:- Puma for Ruby
- Gunicorn3 for Python
- Undertow for Java
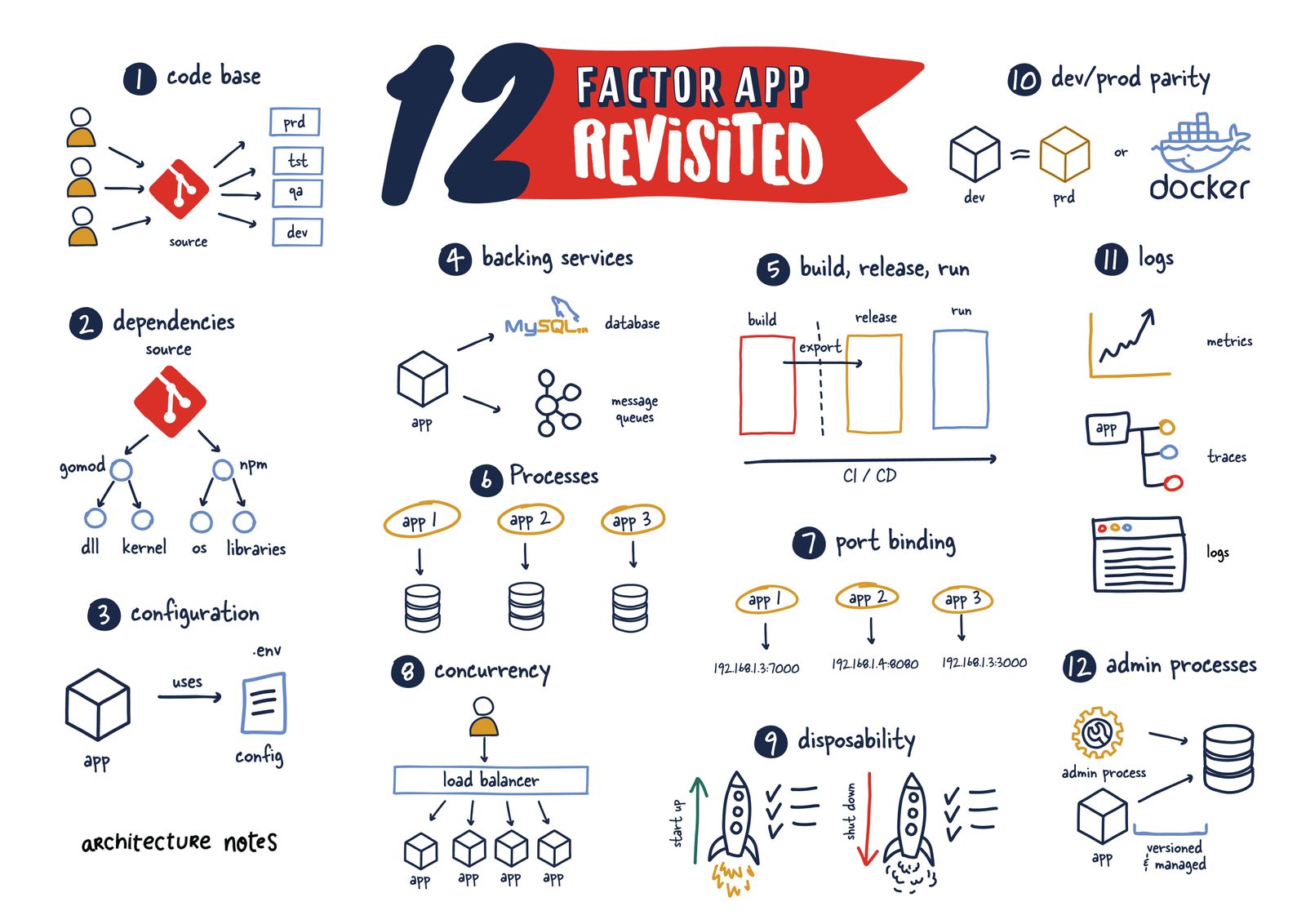
When writing the configuration for your application, use the 12factor principles. The diagram below is copied from the 12 Factor App Revisited article
API Design
- Use the REST](https://www.freecodecamp.org/news/rest-api-best-practices-rest-endpoint-design-examples/) architecture conventions as your guiding principle for naming paths, types of operations and API response statuses.
- Response type: JSON (unless otherwise specified)
- There is an option to open Swagger in your repository to familiarize the next developer with your API design
- It can be written by hand
- Or you can use a codegen: rswag (Rails), safrs (Flask), echo-swagger (Echo/Golang)
If you think that REST+JSON option is not a great fit for your application design, or your task requires using a different format, it could be beneficial to familiarize yourself with some alternatives:
Authorization & Authentication
Authentication - is a process of verifying a user identity. The most common way to authenticate a user is to compare the password they entered with the password saved in the database.
The following strategies can be used to authenticate API users:
- HTTP Basic Auth (easy)
- JSON Web Tokens (a bit more complex)
Authorization - granting a particular user the rights for performing specific actions. For instance: a user who was banned by admin cannot post comments (even though they have been successfully authenticated).
Some examples of libraries:
Additional links:
MVC Explanation
Goal: split the responsibilities between components. MVC is a type of architecture that allows a developer to build applications without excessive cognitive load (compared to other web architecture types)
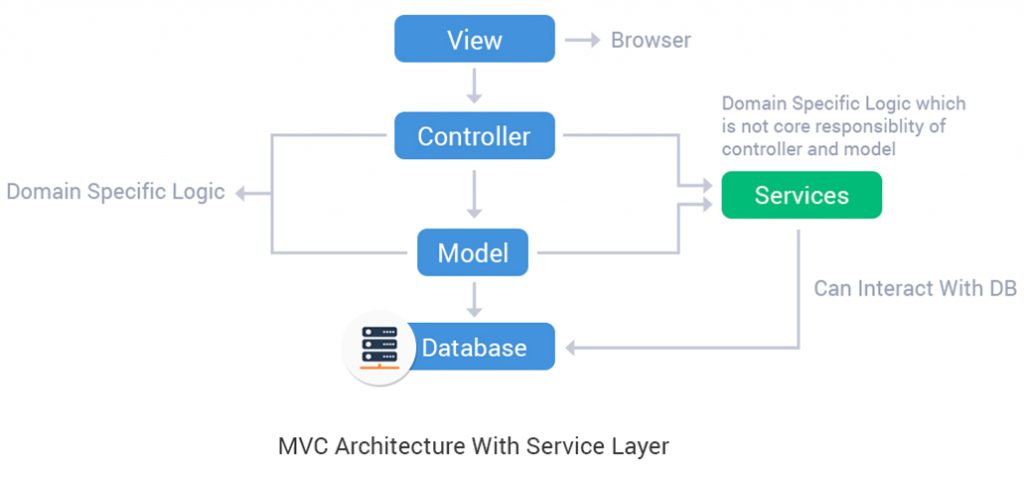
Controller
- Accepts the request and validates request body based on rules set within your API
- Checks authorization + authentication
- Calls a Service and injects data into it
- Based on Service return, a controller formats a response and passes it into a View
Model
- Reflects basic description of schema and relations with other models
- Contains minimum business logic, or ideally none at all
- Is used to make requests to the DB for reads and writes
Service
- Accepts arguments from controllers and validates the request body
- Uses a Model for reading and writing data to DB.
- Is responsible for the business logic of your application
View
- Builds an API response based on data passed to it
📐✏️👷♀️Architecture, Design Patterns, Refactoring, etc
After grasping the concept of MVC, try developing a deeper understanding and study:
- different app architecture approaches
- patterns that can make your code future-proof
A few courses that I recommend:
- Categorized overview of programming principles & design patterns
- Refactoring Patterns and Design Patters Reference
- Summary of “Clean code” by Robert C. Martin
- Summary of “Clean Architecture” by Robert C. Martin
🔒CRUD: Validations
Before persisting data in the database, one should:
- validate the types (e.g. rows that expect string data types receive string data etc.)
- ensure API request body consistency (if a request contains fields that do not have matching columns in the database, these fields should be ignored)
CRUD: Database
- Use and ORM (or a similar tool), unless your requirements specify using pure SQL.
- Easier to operate
- Safe, because most ORMs offer protection against common SQL vulnerabilities out of the box.
- Use migrations to create tables and other entities in your DB (Rails Migrations, Flask-Migrate, etc)
- When describing tables, it is important to specify required constraints (NULLABLE, DEFAULT VALUE, UNIQUE, PRIMARY KEY)
- When describing tables, it is important to specify indices for columns that are expected to be indexed.
- To protect an API from sequencing attacks, you can try using a
uuidinstead of aserial
P.S. Try following the principle of strong migrations to avoid blocking the DB.
CRUD: Operations
LIST (HTTP GET)
- A response should include ID(s) for every resource.
- Resources should be sorted by some type of attribute such as date of creation.
- An API should support pagination to avoid returning all resources at one. Database pagination techniques
- The number of requests to the database within a single API request must be limited avoiding the N+1 queries problem
An API should not return all the fields for a model. Example of a response for a list of articles:
- ID
- Title
- Author name
- First few sentences of the body
Sending a full text body is really unnecessary.
READ (HTTP GET)
- Returning resources with all of their fields. Nothing special here.
CREATE (HTTP POST)
- Filter out fields that should not be accessed by users.
- Commit the INSERT in our DB.
- Send a response with our newly-created resource ID and content.
Bonus points:
- Make sure that the API endpoint is idempotent
- Set up a rate limiter to protect the database from spam
UPDATE (HTTP PUT/PATCH)
- Know the difference between PUT and PATCH HTTP methods
- Filter out fields that should not be accessed by users.
- User authorization check
- Example: users should not be allowed to edit other users’ comments.
- Commit the update depending upon the selected HTTP method.
DESTROY (HTTP DELETE)
- Commit deletion after checking the existing of resource in the database and user authorization
Additionally, you might considering implementing “soft-deletion” (hide deleted resources from users, but keep them in the DB)
External API Calls, Long-running tasks (And why we need message queue)
If an API needs to:
- send requests to third-party resources
- generate reports or perform long requests to DB then it might be a good idea to perform these operations outside of HTTP requests.
To do these operations, we will need a Queue, to which we’ll add or remove Tasks.
Examples of high-level libraries that solve the problem of scheduling, reading and processing tasks:
- Celery for Python (tasks are stored in
Redis) - Sidekiq for Ruby (tasks are stored in
Redis)
It is important to note that Redis is not the only option and it might not be suitable for all types of applications.
Hence, it would be a good idea to learn at least two other advanced libraries for storing and processing queues - RabbitMG an d ‘Kafka’
Additional links:
- Latency, throughput, and availability: system design interview concepts - A more detailed explanation of why fast processing HTTP requests is so important.
📈Logs and Metrics
Metrics:
Set up Prometheus metrick with data about the state of HTTP API and application runtime. We recommend using settings that collect application performance metrics using RED (Rate Error Duration)](https://www.infoworld.com/article/3638693/the-red-method-a-new-strategy-for-monitoring-microservices.html) and USE (Utilization Saturation Errors) methodologies:
Logs:
🛡️Security
- Check library versions you are using for known vulnerabilities. Some utilities that can audit your libraries are:
- bundler-audit for Ruby
- pip-audit for Python
- local-php-security-checker for PHP or the
symfony check:securitycommand, if you are using Symfony framework
- Set up dependabot to check and update library versions
- Ensure that the app is protected against common vulnerabilities - OWASP TOP 10. Here is a tool that can help with this difficult task checklist №1 and №2 (with examples for Ruby on Rails)
CORS Headers (Cross-Origin Resource Sharing)
When dealing with modern single page applications written in popular frameworks like React, Vue.js or Angular, you are likely to encounter a scenario where a client domain will be different from your API domain. In this case, your API will have to include CORS headers to let the browser know that responses coming from the API are permitted.
Typically, a CORS module is already available in your framework of choice and you can use its defaults. If you need more a more granular configuration, here is a few libraries that can help:
You can learn more about CORS headers here here.
🚄Cache
First, try to ask yourself
- “Why do I need it? What problem is it going to solve?”
- “Could I do without it?” (for example, by updating the DB schema, adding indices or optimizing etc)
If you are set on implementing caching, then you’ll need to:
- Choose the cache invalidation strategy based on:
- app business logic
- load profiling (read heavy, write heavy)
- available resources (implementation of certain strategies can be really complex)
- Choose the size and policy for evicting data (because it is impossible to store all of your data in cache). The most popular choice here is Least Recently Used (LRU).
- Choose the storage:
- RAM (in app instances)
- DB (Redis, Memcached, Dynamo, etc)
- Identify the key metrics for measuring the effectiveness (cache hit rate), and be able to change the size or strategy if needed.