how-to-develop-perfect-crud
Translations: EN, RU(you are here)
🤔 Что это?
Данная статья - попытка объединить в одном месте хорошие практики, которые полезно знать и применять при разработке бэкэнд приложения.
Её можно использовать как полноценный чеклист, который будет полезен, если Вы:
- Начинаете новый проект с нуля и сразу хотите заручиться набором хороших практик.
- Получили тестовое задание и всерьез настроены реализовать его.
🤔 Здесь только про Backend?
Так как автор имеет экспертизу только в Backend то и большинство советов будут полезны при разработке Backend приложений. Впрочем многие из советов будут полезны и для других специальностей.
🤔 Слишком много всего, это точно нужно?
Чем больше фич и практик вы реализуете в рамках проекта тем качественнее будет результат. Но реализовать все и сразу может быть сложно и долго, рассчитайте время 🕒 и силы 💪.
🤔 “Здесь не хватает информации о технологии X”
Если у вас есть предложения по наполнению репозитория, не стесняйтесь:
- Предлагать идеи через issues ✅
- Предлагать конкретные изменения через PR ✅
📖 Table of Contents
- Repository
- Code Style
- ✔️Tests
- ⚙️Configuration & Infrastructure around Code
- 🚀Deployment
- Level 0: Use free hostings
- Level 1: SSH, Git, VPS / Cloud (EC2) (without Docker)
- Level 2: Containers and VPS (Docker required)
- Level 3: Containers and clouds (Docker required)
- Level 4: Containers and Orchestrators (Docker required)
- Bonus #1: Learn deployment strategies
- Bonus #2: Shutdown app gracefully with zero downtime
- API Design
- 🧱Authorization & Authentication
- MVC Explanation
- 📐✏️👷♀️Architecture, Design Patterns, Refactoring, etc
- 🔒CRUD: Validations
- CRUD: Database
- CRUD: Operations
- External API Calls, Long-running tasks (And why we need message queue)
- Logs
- Metrics
- 🛡️Security
- CORS Headers (Cross-Origin Resource Sharing)
- 🚄Cache
- Remote Config / Feature Toggles / Feature Flags
- Transactions, Locks, Isolation Levels, ACID
- WIP: Full Text Search
Repository
- Код должен храниться в публичном/приватном Git репозитории (Github / Gitlab / Bitbucket)
- В Git-репозитории должен быть запрещен push с флагом
--forceв основные ветки (master,main, релизные ветки). READMEдолжен содержать:- информацию о проекте
- краткую справку об инструментах и технологиях
- инструкцию по настройке и запуску приложения
- Используйте feature branches, pull requests. Отличная статья в которой сравниваютcя Git Branching Strategies.
- Читаемая история коммитов. Можно использовать практику Conventional commits
- Должен быть настроен Continuous Integration (Gitlab CI / Github Actions)
- Для
feature/иmasterbranches должен быть настроен:- запуск тестов + подсчёт coverage
- запуск линтера
- Будет огромным плюсом если настроен Continuous Delivery - деплой приложения в одно или несколько окружений. (test/stage/prod)
- Необязательно: настроенный dependabot
Code Style
Перед разработкой приложения:
- Настроен редактор или IDE:
- VS Code
- Visual Studio
- PyCharm
- IDEA
- Vim, emacs
- Установлен EditorConfig плагин для твоего редактора
- Установлены наиболее популярные инструменты по верификации качества кода, например
- Rubocop for Ruby
- Pylint/Black/PEP8 for Python
✔️Tests
- Установлены библиотеки для написания тестов различных видов (unit, integration). Например:
- Pytest for Python
- RSpec for Ruby
- Testify, testcontainers for Golang
- После прогона тестов автоматически считается test coverage
- Пишите unit-тесты по паттерну AAA (Arange Act Assert)
Старайтесь покрывать ваш код по пирамиде тестирования. Обратите внимание, что для тестов разного уровня могут использоваться разные инструменты. Для end to end тестирования можно использовать Selenium или Cypress. Для интеграционных удобно использовать testcontainers
⚙️Configuration & Infrastructure around Code
- На локальной машине разработчика установлены
Dockerиdocker-compose - В репозитории есть Dockefile с помощью которого можно собрать приложение в
Docker container- Best practices when writing a Dockerfile for a Ruby application (хотя советы применимы и к другим языкам)
- Google Cloud: Best practices for building containers
- Все зависимости приложения (
PostgreSQL,S3,Redis,Kafka,RabbitMQ) описаны вdocker-compose.yml - Настройка приложения и запуск должны делаться максимально просто и прозрачно (для этого может понадобиться написать вспомогательные скрипты на
bash/zsh/powershell) - Приложение должно иметь несколько окружений (development, prod, test)
- Для
productionсборки приложения используется рекомендуемый application сервер, например:- Puma for Ruby
- Gunicorn3 for Python
- Undertow for Java
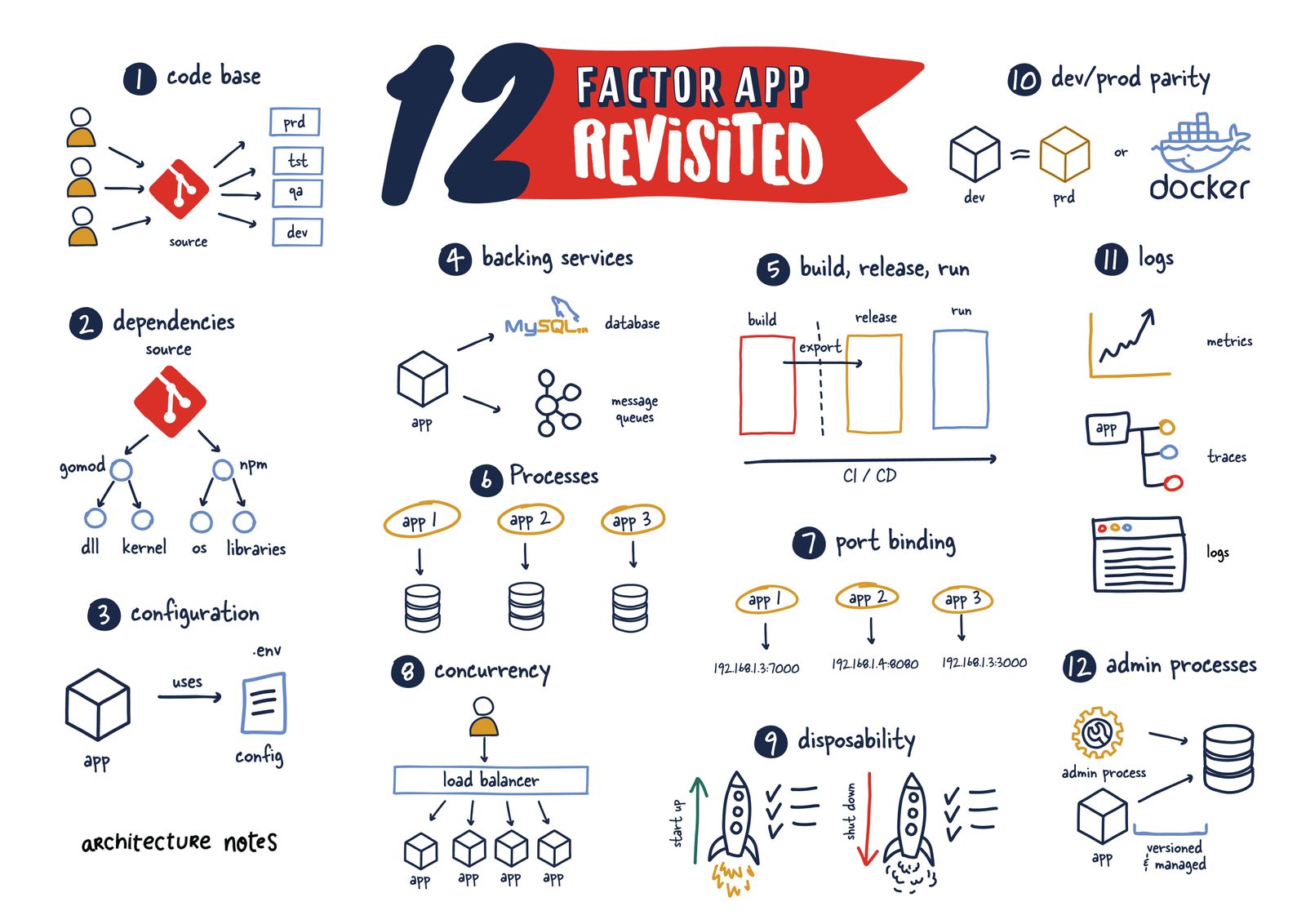
При описании конфигурации приложения используйте принципы 12factor. Изображение взято из статьи: 12 Factor App Revisited
Deployment
В данном разделе будет приведены варианты того как можно задеплоить своё приложение, от простого и топорного до production ready практик.
Level 0: Use free hostings
Многие сервисы предоставляют бесплатный хостинг для небольших проектов, например:
- https://render.com
- https://www.netlify.com
Больше вариантов здесь: https://free-for.dev/#/?id=web-hosting
Изучите их перед тем как переходить к следующим уровням, возможно вам будет достаточно тех фич что они предлагают :)
Level 1: SSH, Git, VPS / Cloud (EC2) (without Docker)
Что требуется:
- Купить сервер у облачного провайдера, убедиться что провайдер выдал вам IP адрес.
- Разобраться с SSH и научиться подключаться к серверу с локального компьютера.
- Установить и настроить утилиты которые обеспечат базовую безопасность сервера
- Установить и настроить на сервере инструменты которые необходимы для развертывания приложения
- Git (для получения новых версий приложения)
- Runtime приложения (нужен для интерпретируемых языков типа Ruby, Python, NodeJS)
- Reverse Proxy (Nginx). Он будет являться точкой входа и заниматься раздачей статических файлов + перенаправлять запросы к приложению
- Настроить автоматическую доставку новых версий кодовой базы на сервер (по кнопке с локального компьютера или например из CI). В этом могут помочь инструменты типа Capistrano, Fabric и многие другие.
Что делать с базой данных? Есть несколько вариантов.
- Настроить на том же сервере (подойдет для тестовых заданий, небольших пет проектов)
- Настроить на отдельном сервере (лучше с точки зрения разделения ответственности но потребует от программиста следить не за одним а 2мя серверами + нужно всё равно понадобится умение конфигурировать, знать лучшие практики)
- Купить managed СУБД у любого провайдера (AWS, Google, Yandex, SberCloud etc). Стоит денег но взамен следить за СУБД будет компания (бэкапы, обслуживание, обновление версий итп)
Дополнительные пункты:
- Купить доменное имя и настроить чтобы запросы к нему шли к серверу
- Настроить Lets Encrypt сертификаты для данного домена + прописать сертификаты в Nginx (чтобы браузер не пугал пользователей сайта о том что сайт небезопасный :))
Задача со звездочкой: научиться писать Ansible playbooks, чтобы настройка сервера выполнялась в одну команду для программиста.
Level 2: Containers and VPS (Docker required)
Данный способ также подойдет для небольших проектов и для тех кто уверенно чувствует себя с Docker.
Что нужно:
- Настроить VPS аналогично Level 1 (SSH, Безопасность, пользователи итп)
- Установить Docker.
- Установить docker-compose на локальной машине разработчика.
Деплой будет происходить через запуск контейнера на удаленной машине:
DOCKER_HOST=“ssh://user@your_vps_domain_or_ip” docker-compose up -d
Таким образом мы мы можем описать приложение и все его зависимости в docker-compose.yml и развернуть в одну команду.
Level 3: Containers and clouds (Docker required)
Если от вас требуется задеплоить приложение в облако и вы уже знакомы с Docker, то всё будет гораздо проще и стандартизовано
Level 4: Containers and Orchestrators (Docker required)
Bonus #1: Learn deployment strategies
Существует несколько способов доставки новых версий приложения. Каждая из них имеет свои плюсы и минусы. Изучите их и выберите наиболее подходящую. Отличный практический репозиторий с объяснениями на примере k8s
Bonus #2: Shutdown app gracefully with zero downtime
Деплой приложения подразумевает что текущие инстансы приложения будут постепенно удаляться и их место займут новые. Чтобы клиент в момент релиза не получил негативный опыт взаимодействия важно перед тем как удалять инстансы терпеливо дожидаться завершения всех клиентских запросов (если речь о HTTP) и не допускать ситуации что в момент деплоя инстанс который завершает свою работу продолжает принимать HTTP запросы.
API Design
- Используй конвенции REST как фундамент при именовании путей, типов операций и выборе статусов ответов API
- Формат данных: JSON (если не требуется другого)
- В репозитории есть возможность открыть Swagger спецификацию для знакомства с API
- Её можно написать самостоятельно
- А можно генерировать c помощью утилит: rswag (Rails), safrs (Flask), echo-swagger (Echo/Golang)
Полезные ссылки:
Если считаешь что связка REST+JSON не подходит под задачу, или по заданию требуется другой формат, то стоит изучить альтернативы:
Authorization & Authentication
Аутентификация – процедура проверки подлинности, например, проверка подлинности пользователя путем сравнения введенного им пароля с паролем, сохраненным в базе данных.
В качестве аутентификации по API можно использовать:
- HTTP Basic Auth (простой путь)
- JSON Web Tokens (посложнее)
Полезные ссылки
Авторизация – предоставление определенному лицу прав на выполнение определенных действий. Например: пользователь которого забанил администратор не может публиковать комментарии к постам (хотя он прошел аутентификацию на сайте).
Примеры библиотек:
Дополнительные ссылки:
MVC Explanation
Цель: разделить обязанности в коде между компонентами. MVC это один из вариантов достижения цели и не требует от разработчика сильной когнитивной нагрузки (по сравнению с другими подходами)
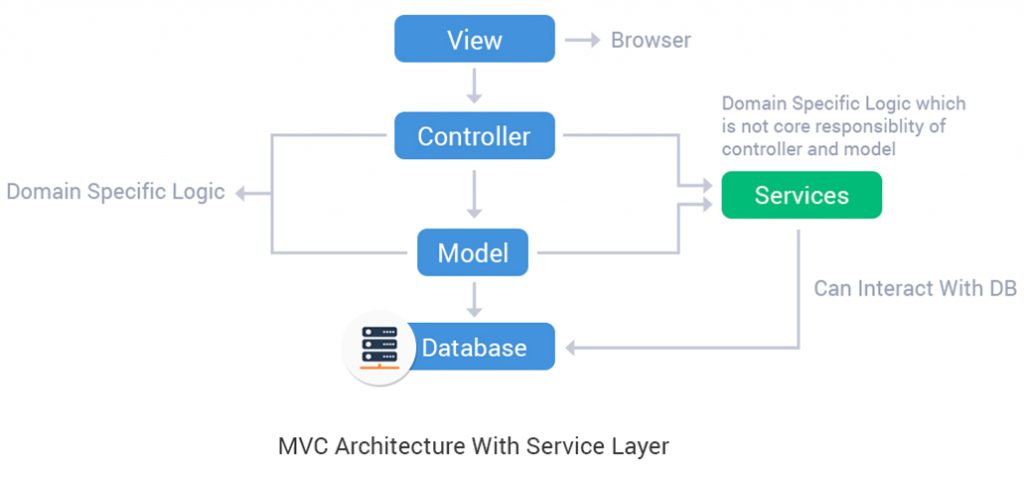
Controller
- Принимает тело запроса, валидирует его на соответствие API
- Проверяет authorization + authentication
- Вызывает Service, передает ему данные
- На основе возвращаемого значения от Service вызывает код формирующий нужный ответ API (через View)
Model
- Хранит только описание схемы данных и связи с другими моделями
- Бизнес логики хранит по минимуму а лучше не хранит вообще
- Используется для того чтобы делать запросы к БД на чтение и запись
Service
- Принимает данные от контроллера, валидирует тело
- Использует Model для чтения или записи данных в БД.
- Отвечает за бизнес-логику приложения
View
- Отвечает за то чтобы на основе данных сформировать API ответ.
📐✏️👷♀️Architecture, Design Patterns, Refactoring, etc
После того как MVC стал открытой книгой стоит углубиться и изучить:
- подходы к построению архитектуры приложения
- принципы которые помогают писать код устойчивый к изменениям.
Бесплатные ресурсы, которые рекомендую для старта:
- Categorized overview of programming principles & design patterns
- Refactoring Patterns and Design Patters Reference
- Summary of “Clean code” by Robert C. Martin
- Summary of “Clean Architecture” by Robert C. Martin
🔒CRUD: Validations
Перед тем как сохранять данные в БД обязательно:
- отвалидируйте данные на тип (там где ожидается строка пришла строка, где int там int итп)
- и соответствие тела запроса API (если пользователь отправил поля которые не имеет права отправлять в БД мы должны их игнорировать)
CRUD: Database
- Используйте ORM (или что-то подобное), если в задании не указано что нужно писать чистый SQL.
- Проще для старта
- Безопасно (Большинство ORM предоставляют защиту от SQL injections из коробки)
- Используйте механизм миграций чтобы создавать таблицы и другие сущности в вашей БД (Rails Migrations, Flask-Migrate, etc)
- При описании таблиц важно сразу указать всем столбцам необходимые constraints (NULLABLE, DEFAULT VALUE, UNIQUE, PRIMARY KEY)
- При описании таблиц важно сразу указать индексы для столбцов по которым ожидается поиск.
- Для защиты API от перебора можно использовать как PRIMARY KEY
uuidвместоserial
P.S. При описании миграций полезно подсматривать сюда, чтобы не написать миграцию которая может заблокировать БД.
CRUD: Operations
LIST (HTTP GET)
- Для каждого ресурса в ответе должно присутствовать ID.
- Ресурсы должны быть отсортированными по какому либо признаку, например по времени создания.
- API должен поддерживать пагинацию (чтобы не возвращать все сущности из БД за раз) Разбор вариантов пагинации + Примеры на PostgreSQL
- Количество запросов к БД в рамках запроса должно быть фиксированным (Отсутствует N+1 проблема)
API не должно возвращать все поля модели. Пример: если наше API возвращает список постов то оно должно возвращать:
- ID
- Название поста
- Имя автора
- Первые несколько предложений статьи (превью)
Полный текст поста для этого эндпоинта не нужен.
READ (HTTP GET)
- Возвращаем полностью ресурс со всеми полями, ничего особенного
CREATE (HTTP POST)
- Валидируем данные на предмет полей которые пользователь не имеет права изменять в БД а следовательно передавать.
- Делаем в БД INSERT
- Возвращаем в ответ ID и содержимое.
Задачи со звездочкой:
- Убедиться что реализованное API идемпотентно: Подробнее
- Настроить Rate Limiter чтобы защитить БД от спама и мусора
UPDATE (HTTP PUT/PATCH)
- Разобраться в чем отличие между PUT и PATCH в HTTP
- Валидировать тело запроса на предмет полей которые пользователь не имеет права изменять в БД а следовательно передавать.
- Проверка права на редактирование у пользователя
- Например API не должно позволять пользователю редактировать чужие комментарии :)
- Реализовать обновление согласно выбранному методу
DESTROY (HTTP DELETE)
- Реализовать удаление предварительно проверив наличие сущности в БД и права на удаление у пользователя
Дополнительно может быть полезно: реализовать soft удаление (скрываем от пользователя, оставляем в БД)
External API Calls, Long-running tasks (And why we need message queue)
Если в рамках API требуется:
- выполнять запросы к внешним системам
- генерировать отчеты/выполнять долгие запросы к БД то стоит подумать о том чтобы делать эти операции за пределами HTTP запроса.
Для этого может понадобиться очередь (Queue) в которую можно будет добавлять задачу (Task).
Примеры высокоуровневых библиотек которых решают задачу с постановкой, чтением и обработкой задач:
- Celery for Python (Задачи хранятся в
Redis) - Sidekiq for Ruby (Задачи хранятся в
Redis)
Стоит отметить, что Redis это не единственный вариант для хранения очереди + не для всех задач он подходит.
Поэтому полезно изучить как минимум 2 более продвинутых варианта для хранения и обработки очередей: RabbitMQ и Kafka.
Доп.ссылки:
- RabbitMQ и Apache Kafka: что выбрать
- Latency, throughput, and availability: system design interview concepts - Подробнее о том, почему так важно чтобы HTTP запросы были быстрыми
Metrics
- Настроить Prometheus метрики с информацией о состоянии HTTP API и райнтайме приложения. Рекомендуется использовать готовые пакеты, которые собирают метрики о работе приложения по методикам RED (Rate Error Duration) и USE (Utilization Saturation Errors):
Logs
- Логи должны писаться только в stdout
- Логи должны иметь строгий формат, например это может быть JSON
- Используйте structured logging подход для явного отделения логируемого сообщения от контекста в котором оно произошло
🛡️Security
- Убедись, что не используешь версии библиотек в которых есть уязвимости, проверять это можно автоматически с помощью утилит, например:
- bundler-audit for Ruby
- pip-audit for Python
- local-php-security-checker for PHP или команда
symfony check:security, если используется фреймворк Symfony
- Настрой dependabot, который будет автоматически обновлять версии библиотек
- Убедись, что приложение достаточно защищено от актуальных уязвимостей - OWASP TOP 10. Помочь в этом нелегком деле может чеклист №1 и №2 (с примерами на Ruby on Rails)
CORS Headers (Cross-Origin Resource Sharing)
Если запросы к твоему API будут делать из браузерных скриптов, например Single Page Application, построенных на современных Javascript фреймворках (React, Angular, Vue.js) и домен API будет отличаться от домена клиентского приложения, то нужно в API добавить CORS заголовки, чтобы браузер не блокировал ответы от API.
Обычно, модуль для настройки CORS заголовков есть в http фреймворке и можно использовать его как по дефолту, так и с более тонкими настройками по необходимости. Например:
Подробнее про CORS заголовки можно прочитать здесь.
🚄Cache
Первым делом нужно задать себе вопросы:
- “зачем нужен кеш, какую проблему он решит?”
- “можно ли обойтись без кеша?” (например изменив схему СУБД, потюнить настройки, добавить индексы итп)
Если твердо решили что нужен кеш то:
- Выбрать стратегию кеширования / инвалидации кеша исходя из:
- логики приложения
- профиля нагрузки (read heavy, write heavy)
- ресурсов разработки (некоторые стратегии достаточно сложны в реализации)
- Выбрать размер кеша + стратегию вытеснения (так как невозможно хранить в кеше абсолютно всё). Наиболее популярной стратегией является Least Recently Used (LRU).
- Выбрать место хранения:
- RAM (в инстансах приложения)
- СУБД (Redis, Memcached, Dynamo, etcd)
- Описать метрику для отслеживания эффективности кеша (cache hit rate) и при необходимости изменять размер кеша или изменить стратегию кеширования.
Remote Config / Feature Toggles / Feature Flags
Для ускорения процесса доставки функциональности полезно использовать динамическую конфигурацию вместе со статической (переменные окружения). Изменения динамической конфигурации позволяет изменить поведение программы без дополнительных деплоев и перезапусков.
Полезные ссылки:
- Фича Флаги и управление ими “по-взрослому”: кейс команды СберЗдоровье
- Open-source feature management solution built for developers.
- Flagr is a feature flagging, A/B testing and dynamic configuration microservice
Full Text Search
Transactions, Locks, Isolation Levels, ACID
Классические веб приложения подразумевают что в единицу времени может быть несколько пользователей (сотни / тысячи / миллионы). И дополнительно к этому пользователи могут взаимодействовать с одним общим ресурсом одновременно (классический сценарий - покупка билетов на мероприятие). Для того чтобы избежать состояний гонки, ошибок и нарушений бизнес-логики важно правильно организовать работу с базой данных как минимум:
- использовать транзакции чтобы не допустить промежуточных состояний.
- избегать конкурентности в критичных местах за счет механизма “lock-ов”